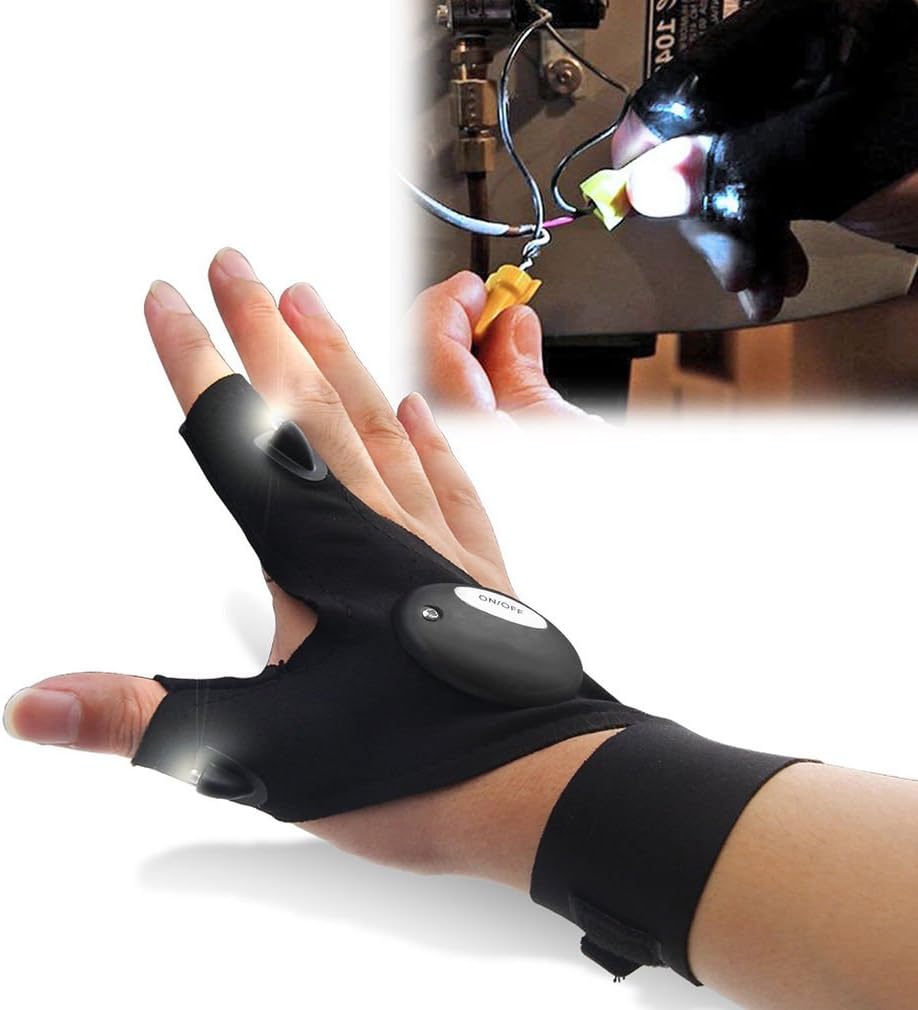
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves 1 Piece Men's Women's Teens One Size fits all XTRA BRIGHT
FREE Shipping
GLOVE TORCH Flashlight LED torch Light Flashlight Tools Fishing Cycling Plumbing Hiking Camping THE TORCH YOU CANT DROP Gloves 1 Piece Men's Women's Teens One Size fits all XTRA BRIGHT
- Brand: Unbranded

Description
In Keras, you can load the GloVe vectors by having the Embedding layer constructor take a weights argument: # Keras code. Portable as a flashlight] this safety rescue gloves can be directly worn on your hands, no need to holding like a traditional flashlight, small and light, simple to use, fully release your hands. Last for a long time, flashlights gloves last about 2-10 hours and you can simply replace the button battery with the screwdriver We can move an embedding towards the direction of "goodness" or "badness": print_closest_words(glove['programmer'] - glove['bad'] + glove['good']) Here are the results for "engineer": print_closest_words(glove['engineer'] - glove['man'] + glove['woman'])
vocab — torchtext 0.4.0 documentation - Read the Docs torchtext.vocab — torchtext 0.4.0 documentation - Read the Docs
self.glove = vocab.GloVe(name= '6B', dim= 300) # load the json file which contains additional information about the dataset Vocab ¶ class torchtext.vocab. Vocab ( counter, max_size=None, min_freq=1, specials=['
PyTorch documentation — PyTorch 2.1 documentation PyTorch documentation — PyTorch 2.1 documentation
torchtext.vocab ¶ Vocab ¶ class torchtext.vocab. Vocab ( vocab ) [source] ¶ __contains__ ( token : str ) → bool [source] ¶ Parameters : It is a torch tensor with dimension (50,). It is difficult to determine what each number in this embedding means, if anything. However, we know that there is structure in this embedding space. That is, distances in this embedding space is meaningful.generating vocab from text file >>> import io >>> from torchtext.vocab import build_vocab_from_iterator >>> def yield_tokens ( file_path ): >>> with io . open ( file_path , encoding = 'utf-8' ) as f : >>> for line in f : >>> yield line . strip () . split () >>> vocab = build_vocab_from_iterator ( yield_tokens ( file_path ), specials = [ "
download and use glove vectors? - nlp - PyTorch Forums How to download and use glove vectors? - nlp - PyTorch Forums
Vectors -> Indices def emb2indices(vec_seq, vecs): # vec_seq is size: [sequence, emb_length], vecs is size: [num_indices, emb_length] High Brightness Lamp Beads - The finger light gloves spotlight with two highlight LED beads, humanized hands-free lighting design which has good performance and comfortable wearing. Great for fishing lover, gadget lover, handyman, plumber, and outdoor work, etc. The word_to_index and max_index reflect the information from your vocabulary, with word_to_index mapping each word to a unique index from 0..max_index (not that I’ve written it, you probably don’t need max_index as an extra parameter). I use my own implementation of a vectorizer, but torchtext should give you similar information. RuntimeError – If token already exists in the vocab forward ( tokens : List [ str ] ) → List [ int ] [source] ¶ The cosine similarity is a similarity measure rather than a distance measure: The larger the similarity, the "closer" the word embeddings are to each other. x = glove['cat']In fact, we can look through our entire vocabulary for words that are closest to a point in the embedding space -- for example, we can look for words that are closest to another word like "cat". def print_closest_words(vec, n=5): We see similar types of gender bias with other professions. print_closest_words(glove['programmer'] - glove['man'] + glove['woman'])
- Fruugo ID: 258392218-563234582
- EAN: 764486781913
-
Sold by: Fruugo